Why it exists
Built because nothing else was enough.
Jayson is building an AI-powered empire — Flexible, adaptive, robust. A creators utopia. It started with a small online booking system. Then it turned into a fully featured photography critiquing website built on php and MariaSQL. He started building helper apps for electronics circuit design, tools, game helpers, professional landing pages. From there it turned into a full stack web development company branded under his own name. If you're going to develop professional websites for business and commerce, you might as well build a proper booking Saas next.
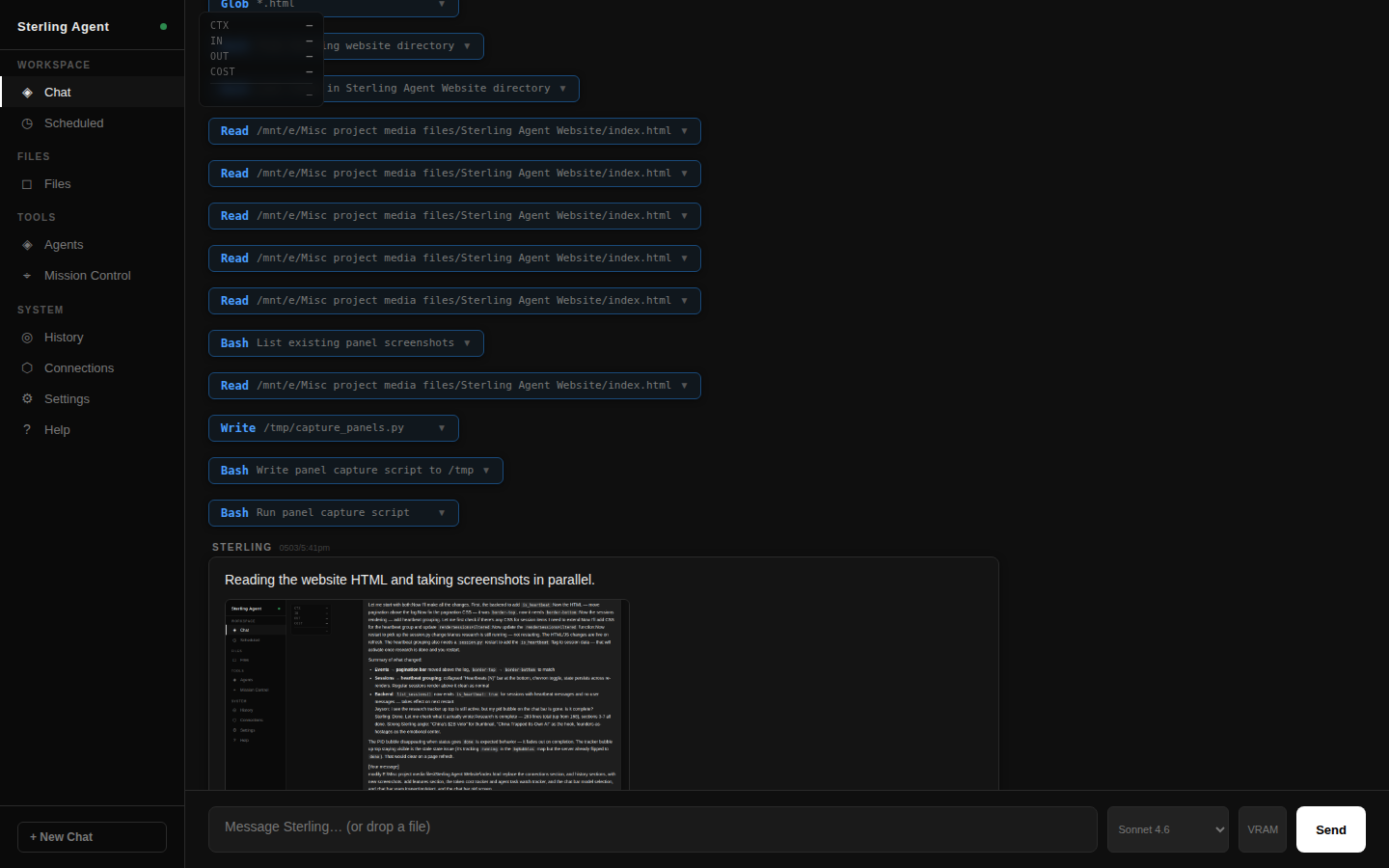
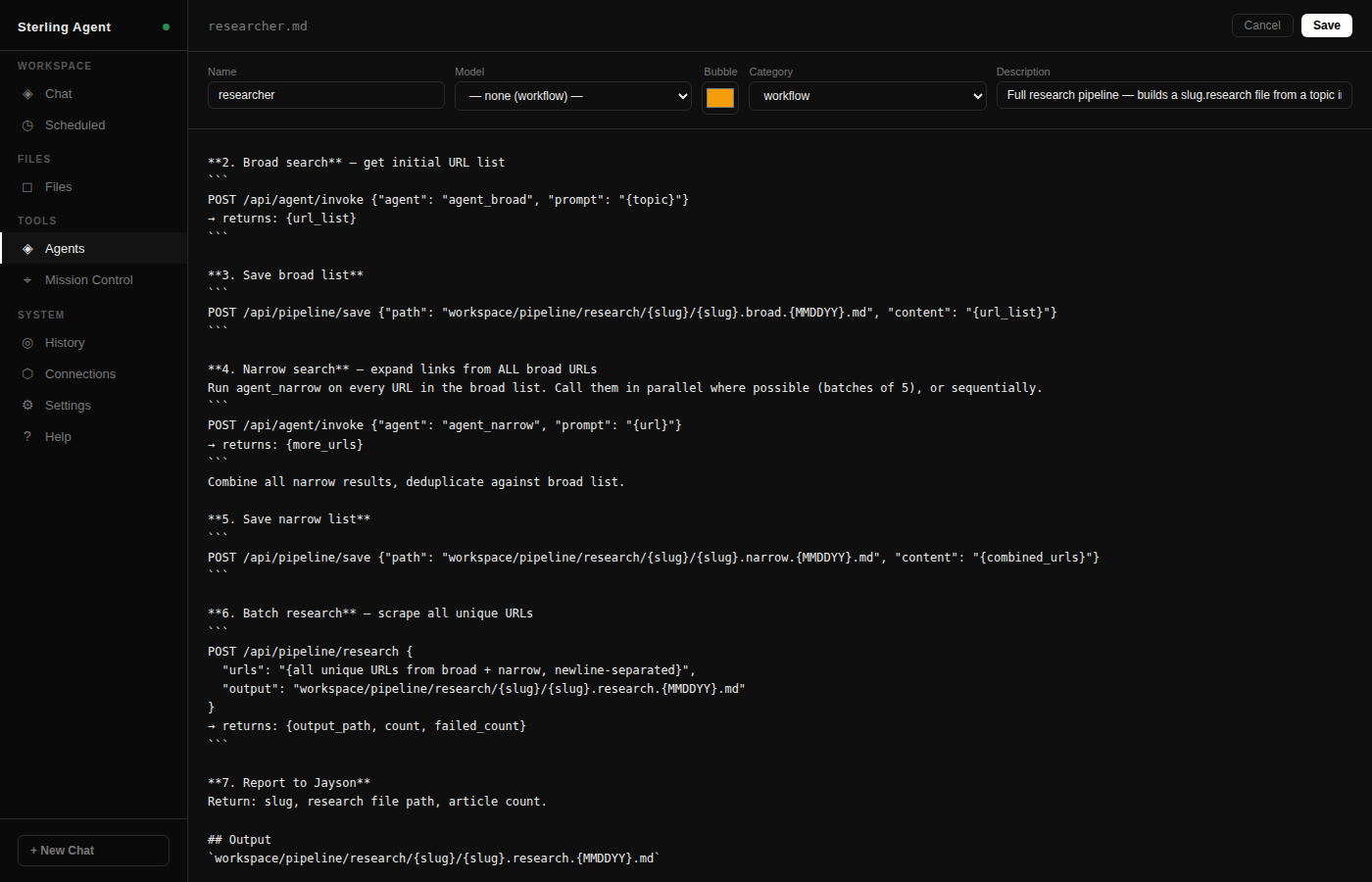
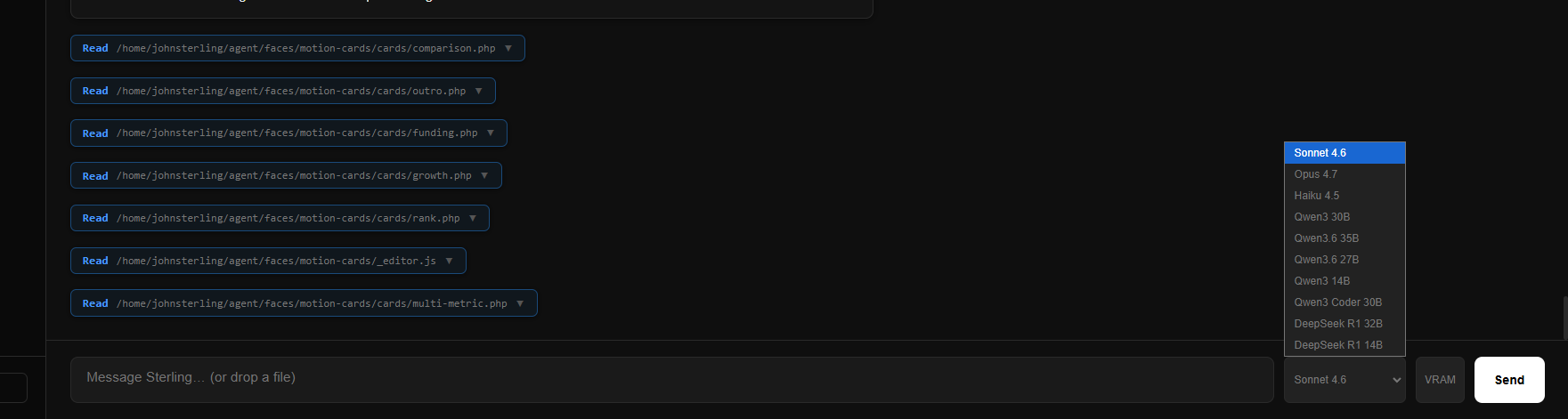
From here he saw the need for more control. He installed OpenClaw. Quickly captivated, but also hugely turned off by the API limits set out by anthropic recently on agents, he needed a new angle. He built his own openclaw. Specificly to work around Anthropics forced API usage on agents and blocking of CLI use. it started as a thin wrapper around Claude CLI.Soon it became a pipe to paralell proceses and invoke more agents. To improve efficiency and build more complexity, faster. This is where Sterling Agent realy took stride.
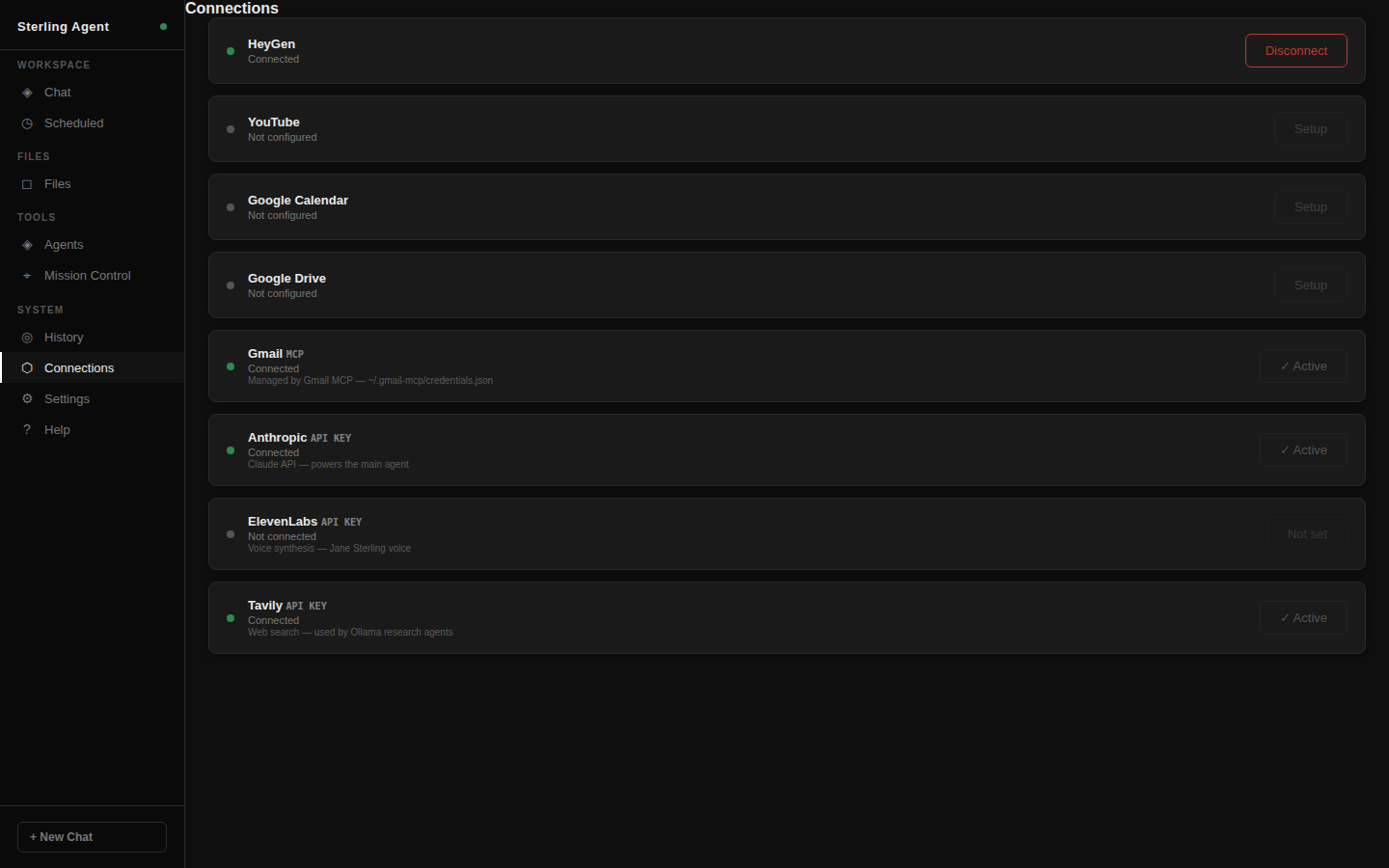
Testing and development of an agent, and a desire to try and automate a complex project, lead Jayson to build an Avatar scripted AI News Channel on YouTube. This obviously needed a website to complement. The news platform is comprised of a daily published long format YouTube video, a targeted short video, and web based news article — each hosted by a fully AI-generated avatar. Every video starts as a topic scrape for direction and then raw information. It ends as a polished production package ready for publish. He learnt how to setup and manage MCP and API connections. He dove into image video and audio genereation. He took many side quests on. Automating along the way. There are still some very manual components; there are also a host of fully automated components. Every day it shifts more towards autopiliot. An evolving pipeline. That pipeline needs an operator.
Off-the-shelf tools weren't it. Generic chat interfaces forget everything the moment
you close them. Cloud assistants don't have access to local files, production workflows,
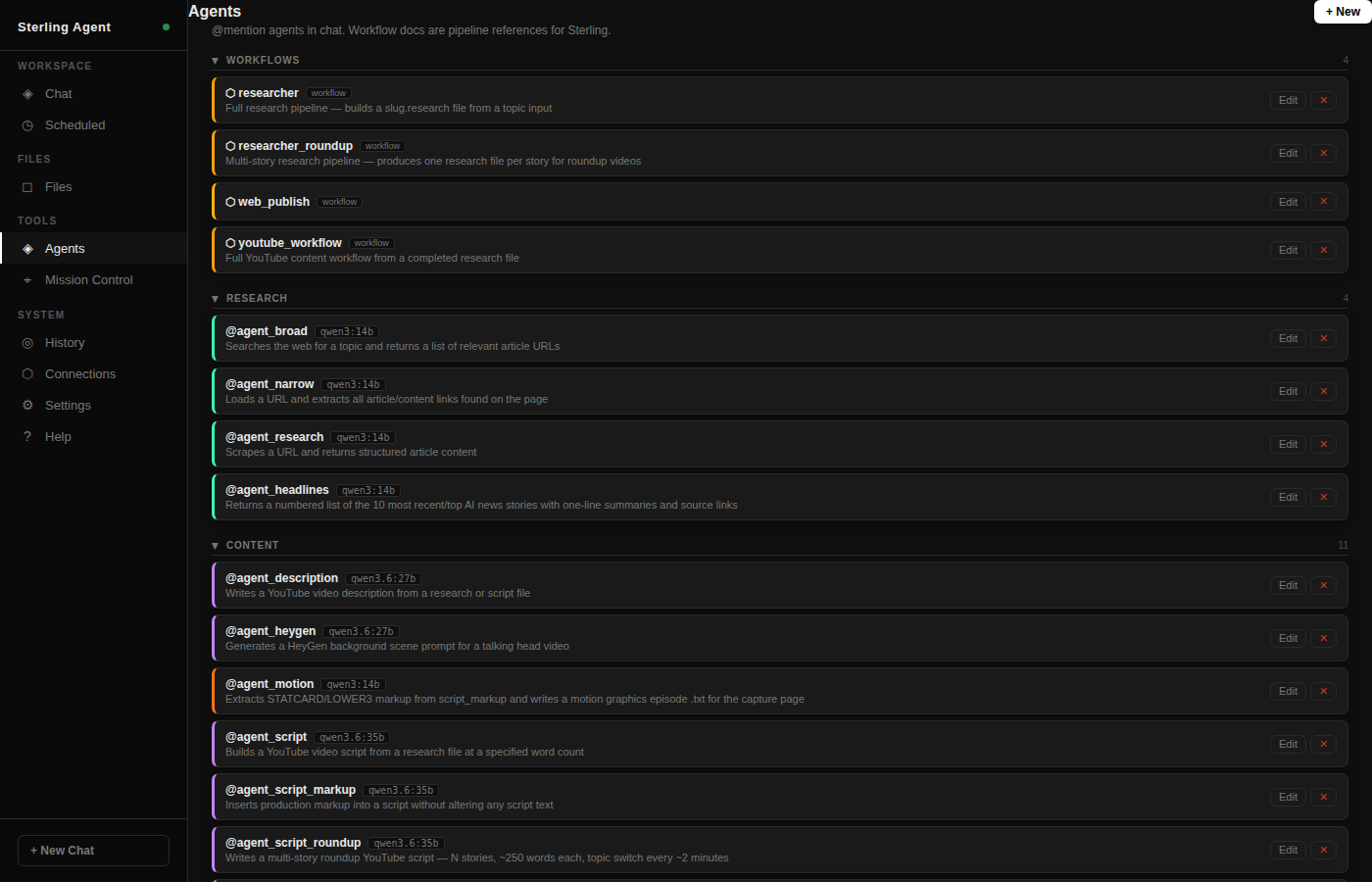
or project context. What was needed was something that could think across sessions,
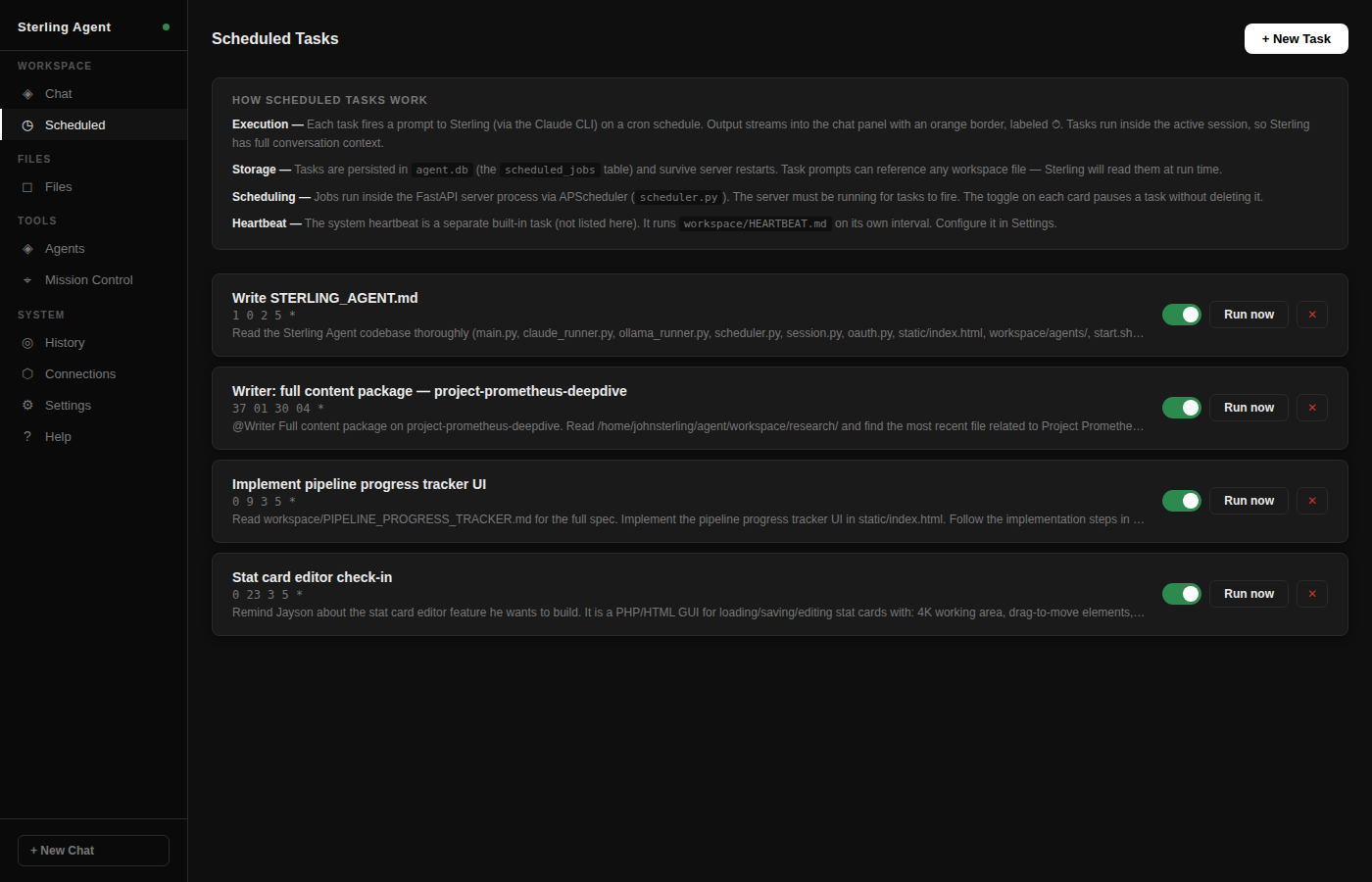
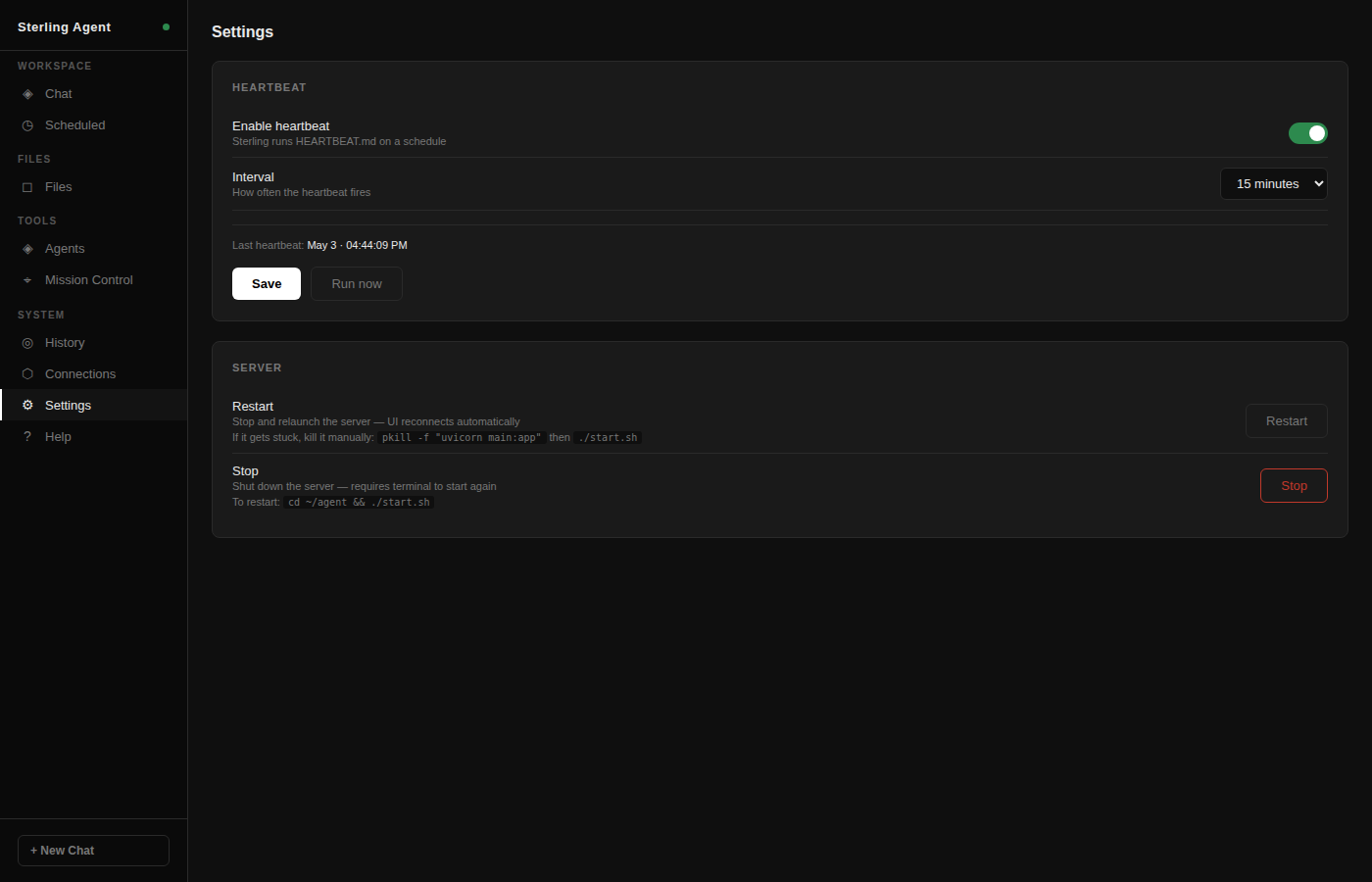
delegate to specialized models, run tasks on a schedule, and keep an entire operation
moving — without constant hand-holding.
So Sterling Agent got built. It started as a thin wrapper around Claude CLI and grew
from there. Every feature added because it was actually needed. Every decision made
in service of real work. It runs locally on a single machine, talks to the browser
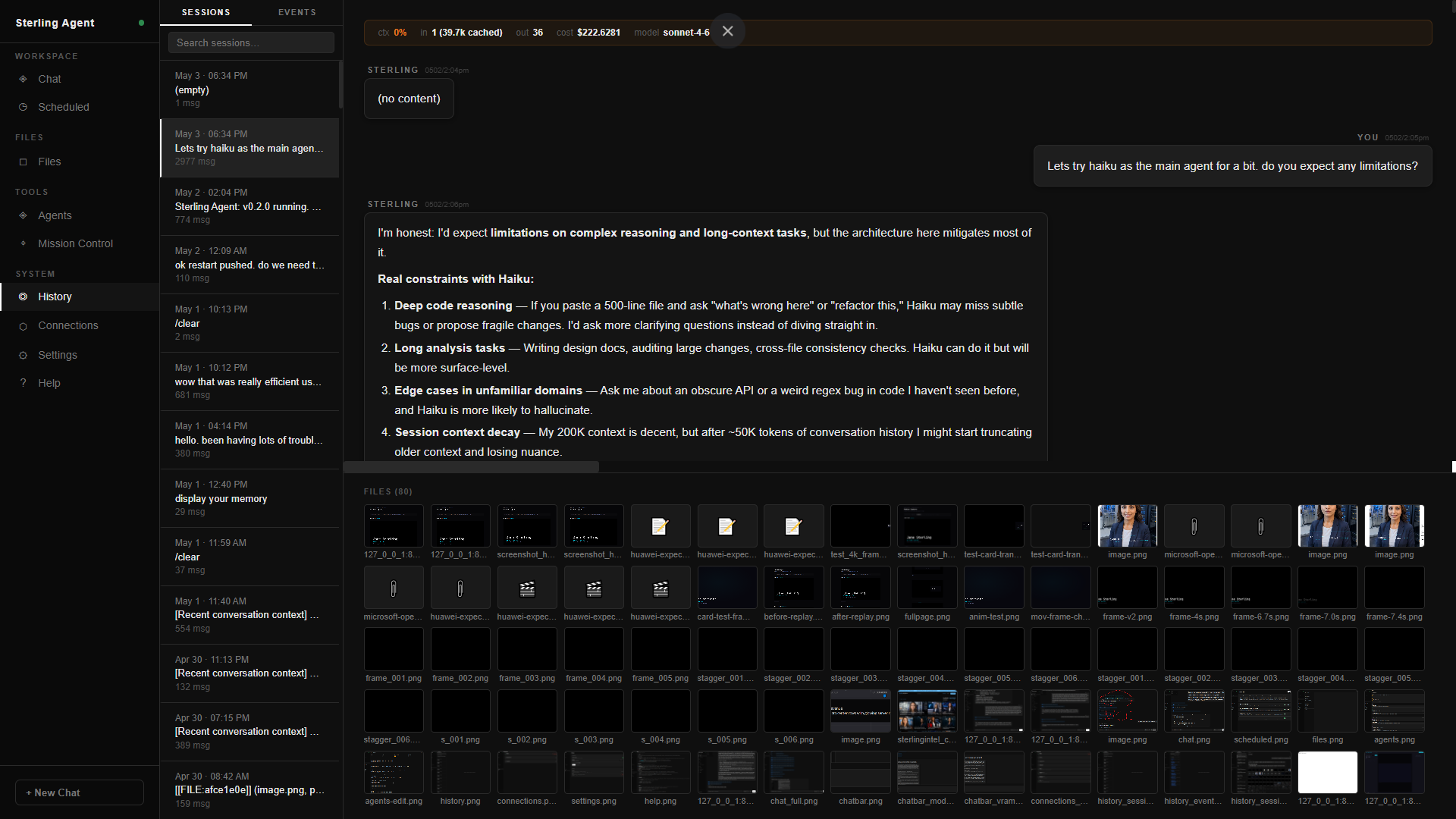
over WebSocket, and maintains persistent memory across every conversation.